
可能你已经使用过ChatGPT,或者你还没有。这都不妨碍AI进入我们世界的现实。
ChatGPT可以实现很多的功能,它可以回答问题,可以撰写文章,可以翻译文字,可以编写代码,可以提供想法等等等等。
但ChatGPT是如何实现这些功能的,它是如何工作的,未来又会怎样演进。
我想,了解这背后的原理和知识,能够帮你更好理解ChatGPT,更好地使用这样一个超级的AI工具。
我通过这篇文章,从非技术人员的视角,小白的视角来看看,ChatGPT是怎样工作。
首先,你要知道的是,当你和ChatGPT进行对话时,你实际上是与一种名为“语言模型”的计算机程序进行交互。
ChatGPT是一种基于GPT架构的大型语言模型,它通过接受和分析你的的输入指令,来生成有逻辑、合理性和连贯性的自然语言输出。
从ChatGPT官方网站OpenAI上可以看到这样一段文字介绍ChatGPT模型方法。

我把这段话输入到ChatGPT,让它来翻译成中文。
得到的结果是:
我们使用人类反馈的强化学习(RLHF)方法训练了这个模型,采用了与InstructGPT相同的方法,但数据收集设置略有不同。
我们首先使用有监督微调训练了一个初始模型:人类AI教练提供了对话,他们扮演了用户和AI助手的双方。
我们允许教练访问模型生成的建议,以帮助他们撰写回复。我们将这个新的对话数据集与InstructGPT数据集混合在一起,并将其转换为对话格式。
为了创建强化学习的奖励模型,我们需要收集比较数据,包括两个或多个模型响应按质量排名。
为了收集这些数据,我们使用AI教练与聊天机器人的对话。
我们随机选择一个由模型生成的消息,采样几个替代的完成方案,并让AI教练对它们进行排序。
利用这些奖励模型,我们可以使用接近策略优化方法对模型进行微调。我们进行了几次迭代这个过程。
这段话的描述里,有这样几个关键字你需要注意:人类反馈的强化学习(RLHF)、监督微调训练、奖励模型。
这几个听上去很专业的名词,其实构成了训练ChatGPT的模型的核心工作原理。只要理解了这三个名词,也就能理解ChatGPT模型工作的核心原理。
在这之前,我们来看一下ChatGPT的英文名字,Chat很好理解,就是对话聊天的意思。而G、P、T三个英文字母,则涵盖了这个对话机器人产生内容的过程。
我们分别来看一下G、P、T是什么。
第一个英文单词是——G (Generative),这里的G是指生成。指的是从给定的输入生成输出,这里的输入可以是我们给的文本,图像或任何其他类型的数据。
在ChatGPT的情况下,输入是一个由用户提出的问题或者对话的上下文,而输出则是ChatGPT生成的回答或者对话继续。
生成可以通过多种方式实现。在ChatGPT中,它是通过对GPT模型进行训练实现的。
在训练期间,模型会学习输入和输出之间的关系,从而可以在测试时生成符合预期的输出。
第二个英文单词是——P(Pre-Training)预训练
预训练是指使用大量的未标注文本数据来训练ChatGPT模型,预就是指提前。
在这个阶段,ChatGPT模型将被训练去自动学习语言的结构和规律。例如,单词之间的关系、上下文信息等等,以此来获得丰富的语言知识。
预训练模型通常使用大型语料库来进行训练,通过大量的数据来喂给ChatGPT,这些语料库包括互联网上的文本、书籍、新闻报道、社交媒体帖子等等。
要记住的是在这些语料库中,没有任何标记或标签(记住这一点,后面会提到打标签)。因此,模型需要通过自学习的方式来尝试理解它们。
请看下面这张图表,列出了预料库来自不同领域,以及他们所占的比重也有所不同。

例如,OpenAI的GPT模型,所给的语料库是不断增加的。
在预训练期间,模型学习了语言的结构和规律,并且能够理解单词之间的关系和上下文信息。这使得模型能够生成连贯且自然的文本,并在各种自然语言处理任务中表现出色,如文本分类、问答系统等等。
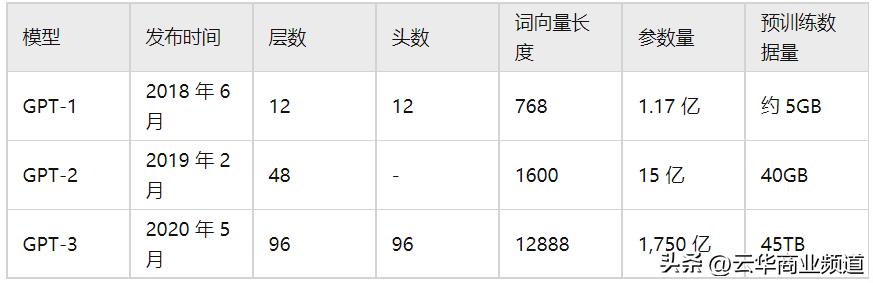
不同版本的GPT的预训练数据量都在惊人地增长,看下面的数据,到了GPT-3的时候预训练的数据量就达到了45TB。
TB什么概念,10的12次方字节,约为1000000000000字节或1024GB。而一个TB又可以储存1000GB的数据。可见,数据量之大。
第三个字母-T,在 ChatGPT 中,T 指的是“Transformer”,是一种广泛应用于自然语言处理任务的深度学习模型。
Transformer 最初是由 Google 在 2017 年提出的,其主要目的是用于机器翻译任务,但很快被证明在许多其他 NLP 任务上也非常有效。
Transformer 的主要特点是能够在处理长序列数据时保持较好的效果,Transformer 采用了一种名为“自注意力机制”(self-attention mechanism)的方法,通过对输入序列中每个元素进行加权聚合,来计算出输出序列的表示。
举个例子:假设我们要训练一个语言模型,给定一段文本中的前几个单词,模型需要预测下一个单词是什么。
为了训练这个模型,我们需要将文本转换成数字形式。比如,将每个单词表示为一个one-hot向量。
如果我们使用传统的神经网络模型,例如全连接神经网络或递归神经网络(RNN),则需要将每个one-hot向量映射到一个低维向量表示,通常称为词嵌入(word embedding)。
然而,这种方法有一些缺点。
首先,由于one-hot向量是高维的,所以矩阵乘法可能会非常昂贵,特别是在处理大量词汇表时。
其次,传统的神经网络模型可能难以处理长序列,因为它们需要在每个时间步骤上进行计算,而计算的复杂度会随着序列长度的增加而增加。
Transformer模型通过使用自注意力机制来解决这些问题。
自注意力机制允许模型在计算嵌入向量时考虑所有其他单词的信息,而不是只考虑输入序列中的前几个单词。这使得模型可以更好地处理长序列,并且不需要像传统模型一样进行矩阵乘法。
举个例子:当我们要做一道数学题时,通常需要进行多步计算。
如果只使用纸和笔来计算,我们需要反复写下计算过程,将中间结果记录下来,并在最后将它们汇总在一起。而使用计算器,就可以让我们更加方便地完成这些计算步骤。
在这个例子中,我们可以把纸笔比作传统的机器学习算法,而计算器就类似于使用Transformer的机器学习模型。
使用Transformer的机器学习模型,就像使用计算器一样,它可以更快速地完成计算,并且不需要像纸笔一样记录中间结果。
这就是Transformer模型的优势所在,它可以更高效地处理数据,从而提高模型的准确性和效率。
讲完了GPT这三个英文字母,你可能大概会了解一些GPT的工作的底层原理,也就是,它是:
√海量数据预先训练的-Pre-Training
√是采用了Transformer模型的自注意力机制
√它是生成式的。
这时,通过GPT(Generative Pre-trained Transformer)方式,其实Chatgpt就可以生成结果了,核心的方法有点类似于我们所说的文字接龙的游戏。
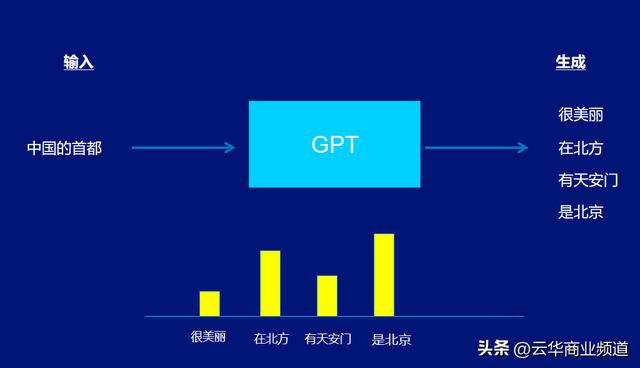
比如,你在ChatGPT中输入:“中国的首都”,它就会生成相关的词,但可能根据它的数据,会有不同的答案。比如,很漂亮、在北方、有天安门、是北京等不同的答案。
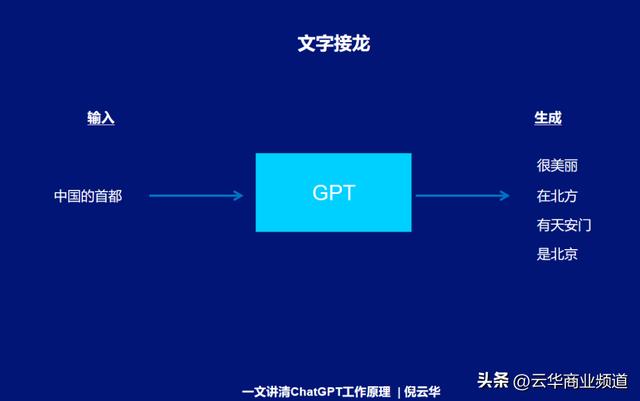
显然,这样的答案是不准确的。
这时候,你可以把ChatGPT理解为一个小孩子,他有一些知识 ,有一些词汇,但是他会不分场合和不分逻辑的讲话。
所以,我们需要对ChatGPT的答案进行Fine-tune(微调),这个时候就需要人工的介入,告诉他我们在这样语言环境,更希望生成的结果是怎样的。
同时,也要告诉他表现的更加善意、具备人的情感,人类更希望的内容。
也就是在预训练之后,对ChatGPT通过有监督微调、奖励模型和强化学习等技术来进一步优化模型以满足特定任务的要求。
原理如图,一共分三步:
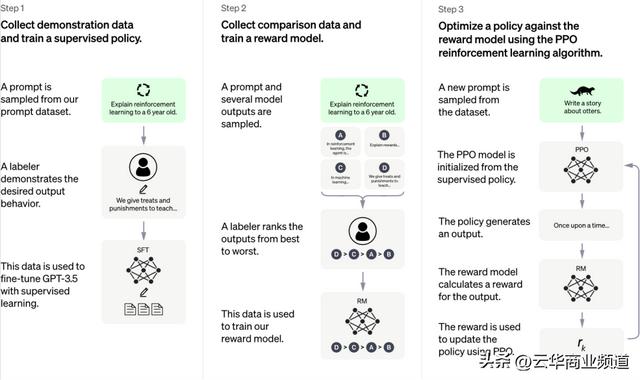
第一步,叫做:监督微调训练。
具体的步骤是,先从指令数据集中选择一些样本,再在这些样本中加入人类期望的回答结果/行为,最后将这些数据生成模型去训练GPT。
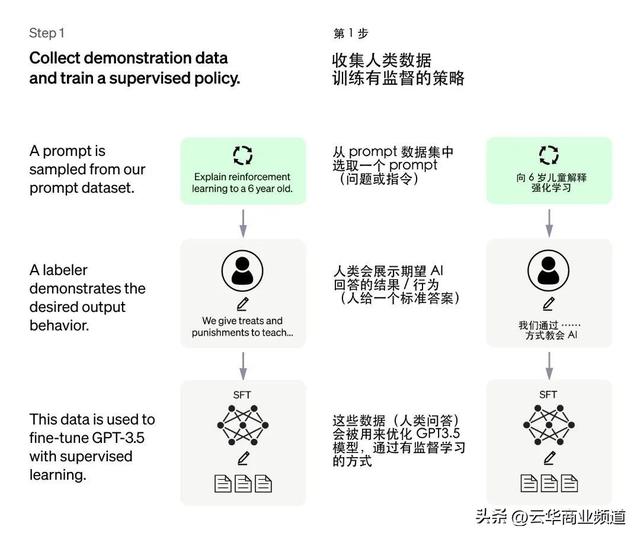
前面的介绍大家知道,ChatGPT最初是在无监督条件下进行训练的,这意味着它使用大量的未标记数据进行训练。
然而,为了使ChatGPT能够更好地适应特定领域或任务,研究人员就开发了有监督微调(SFT)模型。
监督微调(Supervised Fine-tuning,SFT)是一种用于自然语言处理(NLP)的有监督学习方法,它可以根据人类提供的数据对预训练的语言模型进行微调。
SFT模型使用有标签的数据集进行微调,来提高ChatGPT的性能。
例如,当ChatGPT被用于客户服务领域时,可以使用有关客户问题和解决方案的数据集来微调ChatGPT,从而提高它的响应准确性和相关性。
在ChatGPT中,使用了监督微调方法对预训练模型进行微调,以提高对话生成的质量和连贯性。
通常使用人类AI训练师提供的对话数据,让模型学习如何生成自然流畅的对话。
同时,ChatGPT还提供了模型生成的建议来帮助训练师撰写回复。
通过反复微调模型,能够提高模型在对话生成任务上的性能,从而提供更加智能和自然的对话体验。
下面是一些常见的数据标注方法:
「命名实体识别」(Named Entity Recognition,NER):标注文本中具有特定意义的实体,例如人名、地名、组织机构名等等。
「词性标注」(Part-of-Speech Tagging,POS):标注文本中每个单词的词性,例如名词、动词、形容词等等。
「语义角色标注」(Semantic Role Labeling,SRL):标注文本中每个单词在句子中所扮演的角色,例如主语、谓语、宾语等等。
「情感分析」(Sentiment Analysis):标注文本的情感倾向,例如正面、负面、中性等等。
「文本分类」(Text Classification):标注文本属于哪个类别,例如新闻分类、垃圾邮件过滤等等。

“监督微调案例 ”
假设我们想训练一个ChatGPT来帮助用户预订机票。我们可以开始收集人类训练者的对话数据,这些训练者将扮演用户和机器人的角色。
例如,一个训练者可能会说:“我想订一张从纽约到洛杉矶的机票”。
然后,聊天机器人会回答:“好的,什么时候你想去洛杉矶?”
训练者会回答:“我想在下个周末离开纽约,然后在接下来的周末返回纽约。”
这个对话将被记录下来并添加到我们的训练数据中。
然后,我们将这些对话数据输入到ChatGPT的初始模型中进行监督微调。
在微调过程中,聊天机器人将尝试学习如何生成正确的回复来响应用户的请求。
在这个过程中,我们可以利用人类训练者的专业知识来指导聊天机器人的学习,以帮助它更好地理解人类语言并生成更自然的回复。
例如,在我们的机票预订示例中,训练者可以提供一些与机票预订相关的专业术语,如“经济舱”、“头等舱”、“转机”、“直达航班”等等。
聊天机器人将尝试学习如何使用这些术语,并根据用户的请求来提供有用的建议。
随着我们继续训练和微调聊天机器人,它将变得越来越熟练,可以更好地理解人类语言并提供更准确的回复。
比如,上面的案例,经过人类训练师的训练后,对于中国的首都是这个判断,有了更多倾向性的判断,他们的权重是不同的。
可能会给“北京”这个词更高的权重,而"很美丽"给予较低的权重。

“奖励模型 ”
监督微调模型之后的第二步,被称之为奖励模型。
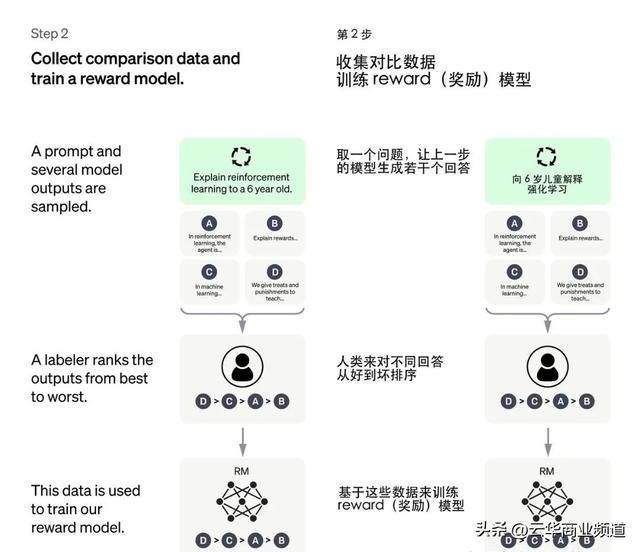
具体而言,奖励模型的工作流程如下:
▼「收集数据」:首先需要收集大量的人工标注数据,包括模型生成的对话响应以及一些其他备选响应。
▼「构建比较模型」:接下来需要构建一个用于比较不同对话响应质量的模型。比较模型可以是基于规则的,也可以是基于机器学习的。
▼「进行比较」:在模型生成对话响应的过程中,从备选响应中随机挑选一些响应,并使用比较模型对它们进行评估,然后将评分返回给ChatGPT。
▼「训练代理器」:ChatGPT会根据比较模型的反馈,利用强化学习的方式训练一个代理器。
代理器会在每次生成对话响应时选择一个响应,并通过比较模型的反馈来优化自己的策略,以便获得更高的回报。
▼「调整生成策略」:通过不断地训练代理器,ChatGPT可以不断调整自己的生成策略,从而提高生成对话的质量和自然度。
比如在前面的例子中,如果AI机器人选择了北京,它就会被给予更高的评分奖励。
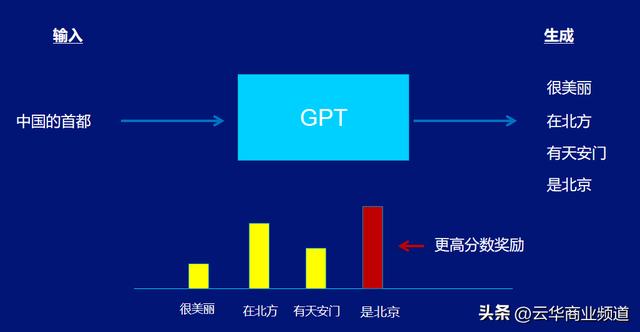
总之,奖励模型的作用是通过与人类专家进行交互,获得对于生成响应质量的反馈信号,从而进一步提升ChatGPT的生成能力和自然度。

“奖励学习案例 ”
假设我们正在训练ChatGPT来提供旅游信息,并且我们希望机器人可以根据用户反馈来改进其回答。我们可以使用奖励模型,来收集用户反馈并改善机器人的表现。
首先,我们需要确定一个指标来评估ChatGPT的回答质量。
例如,训练者可以使用准确性、流畅性和有用性作为指标。然后,我们可以要求用户在和机器人交互时,对机器人的回答进行评价。
假设用户询问:“我想去巴黎,有哪些好玩的景点?”
机器人回答:“巴黎有埃菲尔铁塔、卢浮宫和圣母院等著名景点。”
用户可以选择给予机器人正面或负面反馈,或者不进行评价。
如果用户给出正面反馈,我们可以将其视为一种奖励,并将其加入奖励模型中。
如果用户给出负面反馈,我们可以将其视为一种惩罚,并将其加入奖励模型中。
通过积累足够的奖励和惩罚数据,机器人可以逐渐学习到如何提供更好的回答,以获得更多的正面反馈。
举个例子,如果机器人回答“我不知道”或“我不确定”,用户可能会给予负面反馈,这可以帮助机器人学会更好地回答用户的问题。
另一方面,如果机器人能够提供详细和有用的信息,用户可能会给予正面反馈,这将帮助机器人进一步改善其表现。
通过使用奖励模型,我们可以不断优化机器人的表现,使其能够更好地满足用户需求。

“强化训练 ”
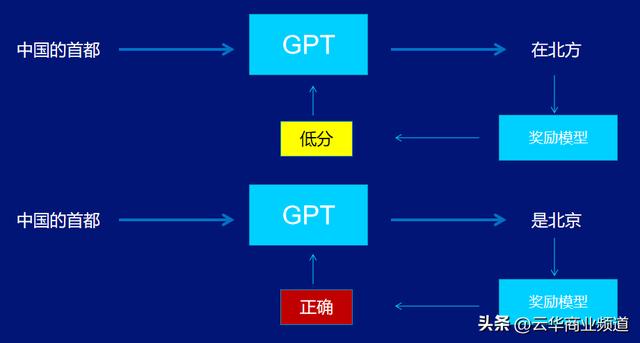
第三步是强化训练。
是基于上一步的奖励模型,使用PPO强化学习来进一步优化GPT。

ChatGPT的强化学习模型基于上下文生成模型和奖励模型进行训练,主要包括以下几个步骤:
▼「收集对话数据」
首先,ChatGPT需要收集大量的对话数据,包括用户和机器人之间的对话,以及机器人自己与自己对话的数据。
▼「训练上下文生成模型」
使用收集到的对话数据,ChatGPT通过有监督学习的方法对上下文生成模型进行训练。
在训练过程中,ChatGPT会将机器人的回复作为输出,前面的对话历史作为输入,从而使模型能够预测出机器人应该如何回复。
▼「构建奖励模型」
ChatGPT需要一个奖励模型来衡量机器人回复的质量。
为此,ChatGPT首先从训练数据中选择一些对话,然后随机生成一些可能的回复,然后将这些回复交给人类评审,让他们对这些回复进行打分。
然后,ChatGPT使用这些打分结果来训练奖励模型,使得模型能够根据当前对话情境评估出机器人回复的好坏程度。
▼「训练强化学习模型」
使用上下文生成模型和奖励模型,ChatGPT开始使用强化学习来训练机器人。
具体而言,ChatGPT使用一种叫做Proximal Policy Optimization(PPO)的算法来训练机器人。
PPO是一种基于策略梯度的强化学习算法,它会通过不断地试错和优化机器人的策略,来最大化机器人的累积奖励。
▼「不断优化」
最后,ChatGPT会不断地优化机器人的强化学习模型,通过不断地试错和反馈来进一步提高机器人的性能。
综上所述,ChatGPT的强化学习模型通过使用上下文生成模型和奖励模型来训练机器人,以最大化机器人的累积奖励。
这种方法使机器人能够根据当前的对话情境自主地做出最佳回复,从而提高了机器人的交互质量和用户体验。

以下是一个简单的强化学习的例子
假设,有一个机器人要学会玩迷宫游戏。
这个迷宫由许多房间和通道组成,机器人需要找到通往迷宫出口的路径。我们使用强化学习来训练机器人。
首先,我们定义机器人的动作。
在这个例子中,机器人可以选择四个动作之一:向上、向下、向左或向右移动一个格子。然后,我们定义机器人的状态。在这个例子中,机器人的状态是它所处的房间。
我们还需要定义机器人的奖励。
当机器人到达迷宫的出口时,它会获得一个正的奖励。但是,当机器人走到死路上或走回已经走过的地方时,它会受到一个负的奖励。
这样可以鼓励机器人尝试找到最短的路径,避免走回头路或陷入死胡同。
接下来,我们让机器人在迷宫中随机移动,并记录它所采取的行动、所处的状态以及所获得的奖励。
然后,我们使用这些数据来训练一个强化学习模型,使机器人能够更好地理解如何在迷宫中移动。
在每次训练后,模型会尝试更新机器人采取不同行动的概率,以便在未来的游戏中做出更好的决策。
经过多次训练后,机器人将能够学习到如何避免死路和回头路,并找到最短的路径,以获得最大的奖励。这就是强化学习的基本原理。
基于前面的例子,ChatGPT不断自我训练,找到符合正常逻辑的答案。
综上所述,ChatGPT是一种强大的自然语言生成工具,它基于Transformer网络架构,使用深度学习、有监督微调、奖励模型和强化学习模型等技术,来生成合理、流畅和相关的对话响应。
通过这些技术的结合,ChatGPT可以提供与人类对话类似的体验,并为用户提供有用的信息和支持。
今天,我们正处于一个过渡点,接下来AI将无处不在。ChatGPT引发的AI浪潮,在规模上与工业革命、电力的发明相当。
未来的竞争,不是人与人工智能AI的竞争,而是掌握AI的人,与未掌握AI的人之间的竞争。
先人一步,掌握当下最流行的AI工具和知识,能让你在未来的生活和职场中具备超级竞争力。


免费交流群:领运营干货,拓展人脉资源,进群备注“进群”,客服微信yunyingquan888
版权声明:除特别注明,本站所有文章均为原创,如需转载请与我们联系。如特别标明作者,版权(文章、图片、视频等)均归作者所有,本平台仅提供信息存储服务,如若转载请联系原作者。

